DiÖ – Cluster B – Beitrag – Blog und Beitrag
Vom Bellen, Singen und Raunzen – und der wissenschaftlichen Beschreibung derselben
Liebes Publikum,
einen schönen Gruß aus dem Institut für Schallforschung der Österreichischen Akademie der Wissenschaften, wo der Wiener Zweig von PP02 sein Zuhause hat und sich der akustischen Betrachtung der österreichischen Dialekte des Deutschen widmet.
Dass es deren mehrere gibt, kann ich wohl getrost als bekannt voraussetzen – und auch, dass sie sich teils drastisch voneinander unterscheiden! Üblicherweise sind die Beschreibungen solcher Unterschiede geradezu poetisch: Da werden Laute als dunkel oder hell, weich oder hart beschrieben, der ganze Sprechvorgang als Bellen oder Singen bezeichnet, und nicht selten mischen sich auch Wertungen darunter wie „gschert“ oder „tief“. Freilich, solche Sinneseindrücke lassen sich jetzt schwer auf einen gemeinsamen Nenner bringen und können je nach Situation ganz unterschiedliche Phänomene bezeichnen. Wie lässt sich der Klang also objektiv im Sinne von nachvollziehbar beschrieben?
Das Instrument Stimme und seine Noten
Hier kommt die Akustische Phonetik ins Spiel. Phonetik – kurz gesprochen – ist die Lehre von den Sprachlauten und dem Sprachklang. Die Akustik ist ein Teilbereich der Physik untersucht den Schall als solches, also sich wellenförmig ausbreitende Unterschiede im Luftdruck. Kombiniert ist der Untersuchungsgegenstand entsprechend der Sprachschall – also das, was aus unseren Mündern (und Nasen) kommt, wenn wir sprechen. Leider ist dieser Sprachschall ein sehr flüchtiges Phänomen und darüber hinaus auch noch unsichtbar. Deswegen behilft sich die Phonetik mit einer bildlichen Darstellung, dem sogenannten Spektrogramm, auf dem genau eingetragen wird, welche Tonhöhe und welche Lautstärke der Schall zu jedem Zeitpunkt einer Tonaufnahme hat. Das schaut dann so aus:
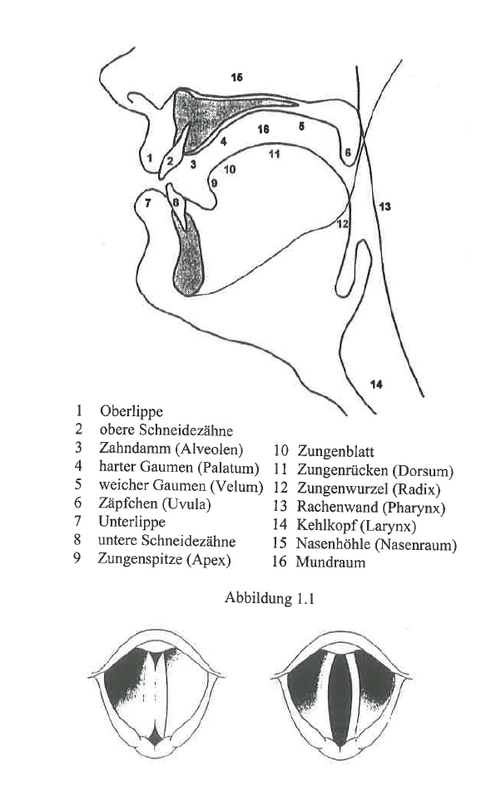
Hier sehen wir eindeutig einen älteren Mann aus dem Ort Kautzen in Niederösterreich das Wort „Käse“ als [kʰaːs] aussprechen. Noch etwas kryptisch? Mit ein paar Beispielen wird die Sache hoffentlich klarer werden! Dazu werfen wir einen Blick auf den Aufbau des menschlichen Körpers:
Wie aber bringen wir die Luft jetzt überhaupt zum Schwingen, sodass Schall entsteht? Dazu verwenden wir unsere Stimmlippen, die im Kehlkopf sitzen. Die können wir dank unserer Halsmuskulatur schnell auf- und zuklappen und damit die Luft aus unseren Lungen beim Ausatmen zum Schwingen bringen. So können wir auch verändern, wie hoch oder tief wir sprechen, was natürlich beim Singen besonders wichtig ist. Diese Tonhöhe, mit der unser gesamter Sprechapparat schwingt, nennt die Phonetik Grundfrequenz. Gemessen wird sie in Hertz; diese Zahl gibt an, wie oft pro Sekunde der Schall schwingt. Bei 100 Hertz also schwingt sie in der Sekunde genau 100 Mal, und generell gilt: Je höher diese Zahl, umso höher auch der Ton. Mit der Grundfrequenz können wir auch schon das Phänomen des „Singens“ erklären: Im Deutschen verändern wir (unter anderem) die Grundfrequenz, um Betonungen anzuzeigen. Wenn also jemand ein Wort betont, sehen wir das als höhere Grundfrequenz. Der genaue Zeitpunkt und der genaue Unterschied sind aber von Sprache zu Sprache, von Dialekt zu Dialekt und auch von Person zu Person unterschiedlich. Deswegen hört sich dasselbe Wort bzw. derselbe Satz plötzlich ganz anders an, wenn dieses Muster sich ändert. Mit diesem Problem kämpfen etwa Deutschlernende, besonders dann, wenn in ihrer Muttersprache Betonung anders funktioniert, zum Beispiel im Ungarischen oder Japanischen.
Mit den Stimmlippen allein ist es aber nicht getan; mindestens genauso wichtig sind die Hohlräume in Kopf und Hals oberhalb des Kehlkopfes Diese bilden einen sogenannten Resonanzraum, ähnlich wie der Bauch einer Gitarre oder, noch treffender, der Röhre eines Didgeridoos. Hier hat die Luft den Platz zum Schwingen, und zwar umso langsamer, je größer der Raum ist. Deshalb haben Kinder, wo das „Rohr“ zwischen Kehlkopf und Mund sehr kurz ist und die Luft entsprechend schnell schwingt, sehr hohe Stimmen, erwachsene Frauen etwas tiefere und Männer die tiefsten. Für ein Beispiel drehen wir ein bisschen an den Einstellungen:
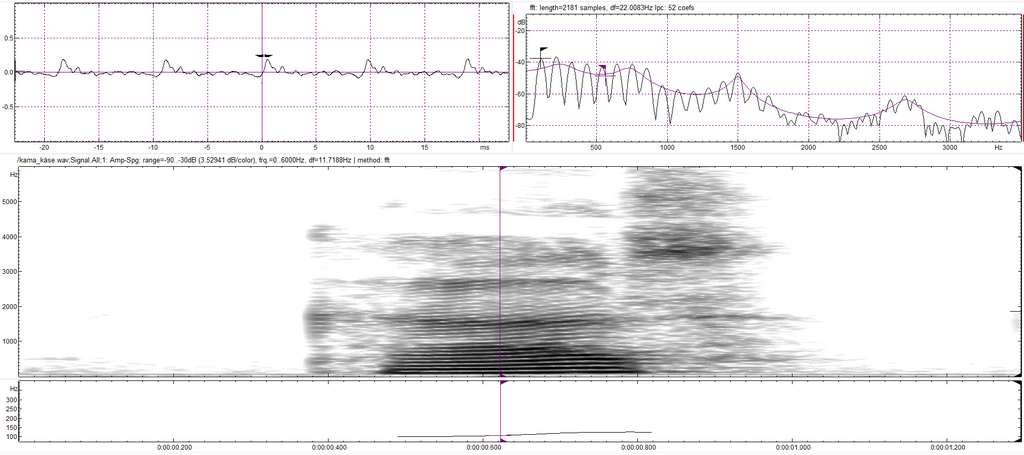
Jetzt treten im Spektrogramm die Grundfrequenz und ihre Vielfachen als dunkle Linien deutlich zutage. Zusätzlich sehen wir rechts oben einen „Schnitt“ durch das „a“ in „Kas“: Die Linien von unten sind Hügel geworden. Der erste Hügel ist die Grundfrequenz bei ca. 106 Hertz – eine typische, tiefe Männerstimme!
Wie sieht nun eine Frau aus? Werfen einen Blick nach Kirchberg am Wechsel:
Die Einstellung sind dieselben, ebenso die Aussprache, aber ein Blick auf unsere Hügel rechts oben zeigt einen viel größeren Abstand. Kein Wunder: Die Grundfrequenz liegt mit 238 Hertz mehr als doppelt so hoch!
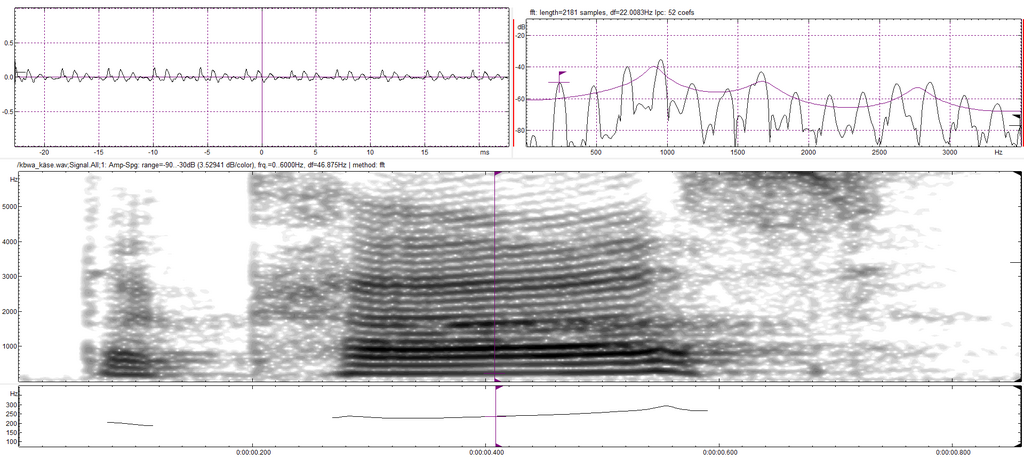
Mit der Grundfrequenz ist es aber noch nicht getan: Um die vielen verschiedenen Laute einer jeden Sprache zu erzeugen, verändern wir diesen Luftstrom noch weiter, indem wir in Mund und Rachen Verengungen oder Verschlüsse bilden – teilweise auch ganz ohne das Schwingen der Stimmlippen, etwa wenn wir bei einem [f] ein Rauschen erzeugen:
Als Beispiel dient wieder unser Sprecher aus Kautzen, diesmal mit dem Wort „Löffel“, realisiert im Dialekt als [lefœ].
Genauso funktionieren im Deutschen das [s], das [ʃ] („sch“), das [ç] (der Ich-Laut, „ch“ nach „i“, „e“, „ü“ und „ö“), das [x] (der Ach-Laut, „ch“ nach den übrigen Vokalen) und das [h].
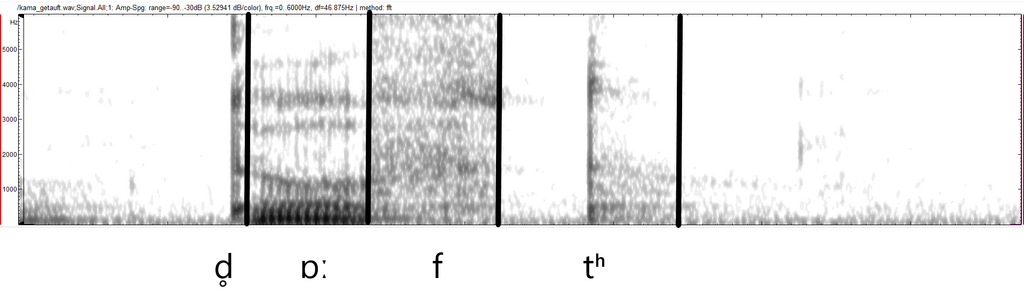
Wenn wir den Luftstrom ganz blockieren und dann in einem großen Schwall wieder freigeben, entsteht ein Verschlusslaut, etwa bei einem [t]. Dazu schauen wir uns unseren Kautzener an, wenn er „getauft“ sagt:
Als Sprecher des Mittelbairischen lässt er natürlich das „ge-„ zu Beginn weg, sodass [d̥ɒːftʰ] überbleibt. Gehen wir ans Ende zum letzten [t], sehen wir zunächst nur weiß, denn hier herrscht Stille: Keine Luft entweicht aus dem Mund. Dann, ganz plötzlich, ist Aktivität über alle Frequenzen zu sehen, wenn die aufgestaute Luft als Schwall entweicht. Dahinter folgt noch ein wenig Rauschen, bis die Luft verbraucht ist.
Die Verwandten des [t] sind einerseits [p] und [k] sowie die stimmhaften Varianten der genannten [b], [d] und [g]. Dieser Unterschied ist im Österreichischen Deutsch jedoch verloren gegangen, wodurch sich die Deutschen wundern, warum hierzulande von „harten“ Ts und „weichen“ Ds die Rede ist – in Deutschland wird der Unterschied nicht nur geschrieben, sondern auch gesprochen.
Nun aber zu den Vokalen, auch als Selbstlaute bekannt. Von den gibt es fünf, oder? A – E – I – O – U! Und vielleicht noch einmal drei, nämlich Ä, Ö und Ü? Nun ja, auch das ist noch zu niedrig gegriffen. Vokale werden nämlich dadurch gebildet, indem die Zunge im Mund eine Engstelle bildet – aber nicht zu eng, sonst würde das Rauschen, wie wir es oben gesehen haben, wieder beginnen! Vielmehr werden dadurch in unserer Röhre zwei weitere, kleine Räume gebildet. Und durch die Resonanz dieser beiden kleineren Räume werden bestimmte Tonhöhen verstärkt, weil die Schwingungen der Stimmlippen in diesen Frequenzbereichen weniger stark gedämpft werden. Dadurch erscheinen sie lauter, also in unserem Spektrogramm dunkler:
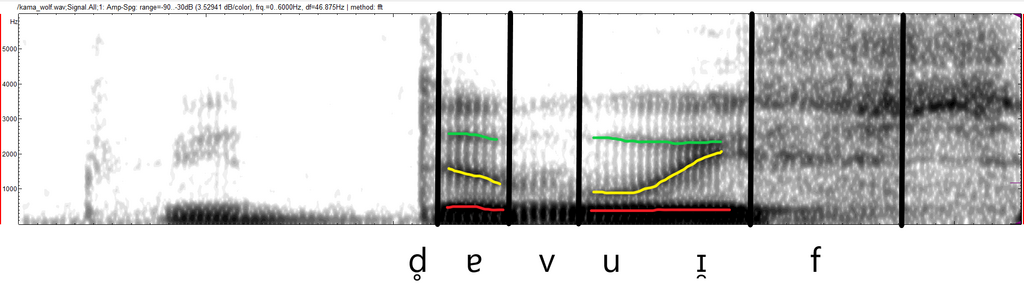
Ich habe mir erlaubt, diese Bereiche farbig nachzumalen. Hören wir unseren Kautzener „der Wolf“ sagen – oder viel eher als „da Wuif“ [d̥ɐ vuɪ̯f] – dann sehen wir deutlich, wie sich beim Übergang vom U zum I etwas tut. Hier nämlich bewegt sich die Zunge von weit hinten im Mundraum nach weit vorn und verändert ihn damit so, dass wir über den Schall die beiden verschiedenen Vokale hören. Dazu orientiert sich unser Gehör an den beiden untersten dieser dunklen Bänder. Die Frequenzen, die uns die Bestimmung eines Vokals ermöglicht, heißen in der Phonetik Formanten. Diese entstehen durch die zeitweiligen Hohlräume, die unsere Zunge im Mundraum bildet. In diesen können bestimmte Frequenzbereiche des Schalls gut schwingen und erscheinen dadurch relativ gesehen lauter als ihre Umgebung.
In unserem Beispiel haben wir den ersten (weil tiefsten Formanten) bei ca. 330 Hertz, im Bild rot markiert. Weil er davon abhängig ist, wie weit wir den Mund beim Sprechen öffnen, verändert er sich vom „u“ zum „i“ kaum – bei diesen beiden Vokalen ist der Mund praktisch kaum geöffnet. Der zweite Formant – oben in Gelb – hingegen steigt stark an, nämlich von ca. 860 Hertz auf beinah 2000 Hertz, was wie bereits erwähnt damit zusammenhängt, dass das [ɪ] viel weiter vorne im Mundraum artikuliert wird als das [u]. Zusätzlich haben wir die Lippen beim [u] gerundet, beim [ɪ] aber nicht, was die Differenz noch einmal erhöht. Daraus ergibt sich dann ein gut wahrnehmbarer Unterschied.
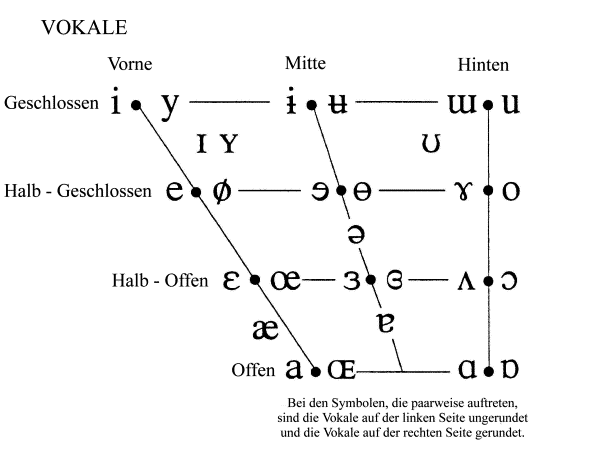
Und damit kommen wir zurück zur Frage, wie viele Vokale es gibt: Da wir die Zunge im Mund frei bewegen können, ist der Übergang zwischen den einzelnen Vokalen fließend. Theoretisch gibt es also unendlich viele feine Abstufungen durch winzige Bewegungen der Zunge. Freilich unterscheidet unser Gehör nicht so genau, sondern ordnet diese Abstufungen bestimmten Kategorien zu. Wie genau wir dabei vorgehen, ist abhängig von den Sprachen, die wir beherrschen und für deren Abstufungen unser Gehirn sozusagen trainiert ist. Für Deutschsprechende ist etwa die Unterscheidung zwischen U und O selbstverständlich, während im Arabischen beides als U wahrgenommen wird. Ähnlich schwer tun sich Englischsprachige mit den deutschen Umlauten Ö und Ü, die im Englischen nicht vorhanden sind – die Liste ließe sich beliebig fortsetzen! Zum Glück ist unser Gehör aber lernfähig und kann sich mit Übung auf neue Kategorien (irgendwann zumindest=)) einstellen.
In der Phonetik unterscheiden wir grundsätzlich zwischen 28 verschiedenen Vokalen, von denen aber in jeder Sprache lange nicht alle gleichzeitig vorkommen
Für das Standarddeutsche kommen wir in Regel mit 14 Vokalen aus, im Österreichischen Standard sind es eher noch weniger. In den Dialekten ist die Lage natürlich noch einmal anders, was die Sprachwissenschaft seit über hundert Jahren gut auf Trab hält…
Mit dieser Beobachtung werde ich diesen Beitrag zunächst einmal schließen, denn er ist ja schon ziemlich lang geworden. Natürlich ist mir bewusst, dass noch nicht alle Fragen beantwortet sind, die ich zu Beginn aufgeworfen habe, aber es muss ja nicht bei einem einzigen Beitrag bleiben…=)





In: DiÖ-Online.
URL: https://iam.dioe.at/blog/1629
[Zugriff: 30.07.2026]