DiÖ – Gesamt-SFB – Beitrag – Blog und Beitrag
Es (PRON) war (AUX) einmal (ADV): Die linguistische Annotation von Sprachdaten im SFB
Eigentlich ist das sprachwissenschaftliche Arbeiten manchmal ziemlich märchenhaft. Das liegt nicht nur an der Verbindung zu den Gebrüdern Grimm, die in sprachwissenschaftlichen Kreisen vor allem für das Grimmsche Wörterbuch bis heute relevant sind. Nein, manchmal dürfen sich Sprachwissenschafter*innen selber wie Märchenfiguren fühlen – dabei geht es weniger um die drachentötenden Heldinnen oder gewitzten Bauernkinder (wobei der Bote, der Rumpelstilzchens Namen herausgefunden hatte, durchaus als früher Onomastiker, also als Namenskundler, gelten darf) – sondern viel mehr sehr konkret um die Tauben, die Aschenputtel beim Sortieren der Linsen geholfen haben. Denn was war „die Guten ins Töpfchen, die Schlechten ins Kröpfchen“, wenn nicht eine frühe Form der linguistischen Annotation?
Wie aus „Linsen“ Token werden
Zugegebenermaßen ist diese relativ einfache Form der Kategorisierung (gut = Töpfchen; schlecht = Kröpfchen) ziemlich weit entfernt von der Kategorisierung von Sprachmaterial, wie sie Linguist*innen betreiben. Diese Kategorisierung von Sprachdaten nennen wir gemeinhin ‚Annotation‘ – wir weisen gewissen Token (das sind einzelne Wörter) bestimmte Labels (sogenannte ‚Tags‘) zu, die diese näher kategorisieren und bestimmen. Eine sehr verbreitete Form dieses Taggings kennen die meisten wohl auch noch aus der Schule, wenngleich mit anderem Namen – das sogenannte POS, oder Part-of-Speech Tagging. Dabei werden die Wortarten der einzelnen Token bestimmt – also ob es sich um Adverbien, Adjektive, Substantive usw. handelt. Im Gegensatz zu Übungsblättern in der Schule geschieht diese Zuweisung allerdings heutzutage meistens automatisch – so auch beim SFB.
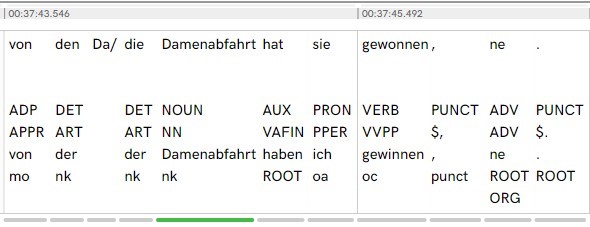
Bei diesem Ausschnitt aus einem unserer Interviews sieht man die Part-of-Speech-Tags, die den Token zugewiesen wurden. Der SFB hat zwei verschiedene Programme verwendet, um das Datenmaterial zu taggen – daher erklärt sich auch das unterschiedliche Vokabular, das in dem Screenshot verwendet wird. Der eine Tagger (spaCy) bezeichnet zum Beispiel das Token „die“ als determiner (DET); während der andere Tagger (STTS) das Label Artikel (ART) vergibt. Richtig ist beides: die Label, die spaCy vergibt, sind allerdings weitaus unspezifischer, und nicht direkt auf einzelne Sprachen zugeschnitten, während STTS – das sogenannte Stuttgart-Tübingen-Tagset – für die deutsche Sprache entwickelt wurde, und die vergebenen Tags daher genauer sind. Die Verwendung automatischer Tagger hat zwei Vorteile: einerseits ist es wohl die einzige Möglichkeit, die Menge an Daten überhaupt mit Part-of-Speech Tags zu versehen (hätte Aschenputtel so viele Linsen sortieren müssen, wie der SFB einzelne Token hat, dann würde die Disney-Verfilmung wohl eher an Hitchcocks „Die Vögel“ erinnern), andererseits sind die Daten so uniform: Was in einem Transkript als Artikel erkannt wird, wird nach den gleichen Kriterien in einem anderen Transkript ebenfalls als Artikel erkannt. Außerdem ist die Annotation mit z.B. STTS ein Standard für viele deutschsprachige Korpora, also Datensammlungen, was heißt, dass nicht nur einzelne Transkripte miteinander vergleichbar sind, sondern unser ganzes Korpus mit anderen Korpora.
Wie sich das „Topferl“ vom „Töpfchen“ unterscheiden lässt
Diese automatische Form der Annotation ist allerdings nur ein sehr kleiner Teil der Annotation im SFB. Die Annotation, die mehr Zeit – und mehr unseres Forschungsinteresses – in Anspruch nimmt, ist die Annotation von linguistischen Phänomenen aller Art. Um noch einmal auf Aschenputtel zurückzukommen – hier müssen unsere Tauben Wissenschafter*innen nicht zwischen „gut“ und „schlecht“ unterscheiden, sondern eher zwischen lens orientalis und lens culinaris. Anders gesagt: Hier ist einiges an Hirnschmalz und Genauigkeit gefragt.
Die Annotation linguistischer Phänomene funktioniert nämlich ein wenig anders als das POS-Tagging: Während beim POS-Tagging einzelne Token bereits etablierten Kategorien zugewiesen werden (z.B. „die“ ist ein „Artikel“, „gewonnen“ ein „Verb“), so müssen für die Annotation der linguistischen Phänomene erst einmal die Kategorien erstellt werden, mit denen das Phänomen beschrieben werden kann. Ein Beispiel soll das verdeutlichen:
Eines der Phänomene, die vom SFB etwa untersucht werden, ist die Diminuierung, also die Bildung von Niedlichkeitsformen, wie etwa „Täubchen“ von „Taube“. Eine Kröpfchen-Töpfchen Annotation wäre, jedes einzelne Token nur danach zu annotieren, ob es ein Diminutiv ist, oder nicht. Diese wäre zwar logisch klar, sagt allerdings relativ wenig über die verschiedenen Dimunitiva aus – sie ist linguistisch nicht besonders ergiebig. Eine solche Annotation würde nur einen Zweck erfüllen, nämlich dass sich die Token leicht wiederfinden lassen. Eine gute Annotation kann aber weit mehr leisten – sie kann das linguistische Phänomen in seiner Ausprägung klassifizieren.
Wir verwenden daher für die Annotation der linguistischen Phänomene ein hierarchisches Tagset. Während ein flaches Tagset relativ einfach zu konzipieren ist – man vergibt ein Label, einen Tag, wie etwa „Adjektiv“, „Adverb“, „Artikel“ usw., oder auch einfach „Diminutiv“ und „nicht-Diminutiv“, kann ein hierarchisch aufgebautes Tagset durchaus komplizierter werden. Dafür kann es aber viel mehr Informationen liefern und eine genauere Kategorisierung ermöglichen. Bleiben wir bei den Diminutiva: Wenn wir etwa die Folgenden vergleichen, wird schnell klar werden, warum ein hierarchisches Annotationssystem besser geeignet ist, als einzelne Label:
Stückchen – Pupperl – Kaffeetscherl – Käffchen
In einem flachen Annotationssystem wären alle diese Formen gleich zu annotieren – sie sind alle vier Diminutiva. Dabei unterscheiden sich diese Formen gravierend. Die erste und die vierte Form enden zwar beide auf -chen, während aber im vierten Beispiel der Vokal wechselt (aus Kaffee wird Käffchen), bleibt er im ersten Beispiel gleich (Stück bleibt Stückchen). Das zweite und dritte Beispiel haben zwar die gleiche Endung (-erl), und bei beiden bleibt der Vokal gleich, dafür tritt im dritten Beispiel zusätzlich zur Endung -erl noch mehr dazu. Es heißt nicht *Kaffeeerl, sondern Kaffeetscherl, mit einem zusätzlichen -tsch- (in der Sprachwissenschaft wird so etwas als „Interfix“ bezeichnet – analog dazu heißt Wortmaterial, welches vor ein Wort tritt, Präfix, und welches ans Ende eines Wortes tritt Suffix). Kurz gesagt: auch wenn alle diese vier Beispiele Diminutiva sind, reicht es für sprachwissenschaftliche Zwecke nicht, sie nur mit diesem Tag zu versehen. Als Linsen würden sie zwar alle in den Topf (bzw. ins Töpfchen - oder Topferl?) kommen, aber wir stellen in der Sprachwissenschaft höhere Ansprüche als fiktionale Stiefmütter bei Hülsenfrüchten.
Wie Tags zu unseren „Kindern“ werden
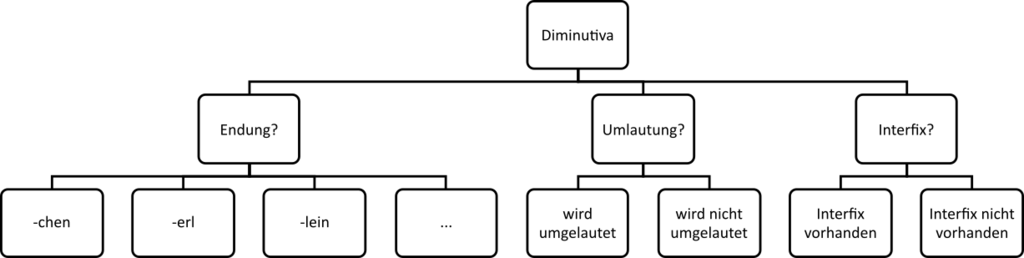
Die oben erwähnten Unterschiede werden als verschiedene Kategorien in unserem Tagging-System formalisiert. Graphisch kann man sich das in etwa so vorstellen:
So könnte ein Annotationssystem aussehen, das alle Informationen beinhaltet, die zuvor erwähnt wurden. Dieses Diagramm lässt sich von oben nach unten lesen, und man verwendet dabei eine Familienmetapher: Die Tags, die direkt miteinander verbunden sind, werden als „Kinder“ bezeichnet (der Tag „Endung?“ ist z.B. das Kind des Tags „Diminutiva“), man spricht dabei von „Generationen“ (der Tag „Endung?“ ist dabei auf der ersten Generation, der Tag „Diminutiva“ auf Generation 0). Die Tags folgen einer internen Logik: Während sich die Tags auf Generation 1 ergänzen (die Fragen „Endung?“, „Umlautung?“, „Interfix?“ treffen auf jedes Diminutiv zu), schließen sich deren Kinder auf Generation 2 aus (eine Umlautung ist entweder vorhanden, oder nicht vorhanden – sie kann nicht beides sein; genauso wie ein konkreter Diminutiv nur eine Endung haben kann). Dieses (vereinfachte) Annotationssystem würde also, auf unsere Beispielwörter bezogen, so aussehen:
Stückchen: Diminutiv → Endung → -chen | Umlautung → nicht umgelautet | Interfix → nicht vorhanden
Pupperl: Diminutiv → Endung → -erl | Umlautung → nicht umgelautet | Interfix → nicht vorhanden
Kaffeetscherl: Diminutiv → Endung → -erl | Umlautung → nicht umgelautet | Interfix → vorhanden
Käffchen: Diminutiv → Endung → -chen | Umlautung → umgelautet | Interfix → nicht vorhanden
Es erlaubt uns, die Wörter genau zu kategorisieren – und macht damit die Arbeit mit großen Datenmengen einfacher, denn durch die genaue Kennzeichnung wird es uns möglich, nur bestimmte Subsets im Detail anzusehen (z.B. Diminutiva, die auf -chen enden und umgelautet werden). Alle unsere linguistischen Phänomene werden mit solchen hierarchisch aufgebauten Annotationsschemata annotiert – egal, ob es um die Aussprache einzelner Laute, die Stellung von Wörtern im Satz, die Bildung neuer Wörter (wie z.B. bei Expressivkomposita), oder den Kontext, in dem bestimmte Wörter verwendet werden, geht. Für all diese Phänomene versuchen wir, relevante Kategorien (und damit Annotationen) zu finden, um mit diesen unsere Daten zu analysieren. Die Vielfalt der Phänomene spiegelt sich auch in der Anzahl der Tags wieder: mittlerweile finden sich knapp 875 verschiedene Tags in der Datenbank.
Selbstverständlich wird es in der Praxis oft viel komplexer als im oben genannten Beispiel. Gerade im Deutschen in Österreich findet sich sehr viel Variation, und nicht alle linguistischen Phänomene lassen sich einfach mit leicht unterscheidbaren Kategorien beschreiben. So werden unsere Annotationsmeetings, analog zu den Tagging-Systemen, schon mal zu Familientreffen, in denen stundenlang über die verschiedenen Tags und Arten der Annotationen sinniert und diskutiert wird. Das Korpus des SFB bietet uns Material für unendlich viele weitere Analysen und wird uns durch seine Vielfalt noch ewig beschäftigen - in diesem Sinne: „Und wenn wir nicht gestorben sind, dann annotieren wir noch heute.“
In: DiÖ-Online.
URL: https://iam.dioe.at/blog/2837
[Zugriff: 27.07.2026]